Automating company research
This automated research system takes a name and URL and gathers company and news data, validates AI-generated profiles, identifies useful interview angles, and delivers briefs to Notion.
What it is
The Sustainablest Research tool automates the first pass of company research for the Sustainablest website, an interview project that explores the challenges and solutions for companies working sustainably.
When given a company name, website, and optional notes, the tool reads the company’s site, searches for recent news, and builds a structured profile covering its product, customers, funding, recent activity, and possible interview angles.
This workflow runs via:
- a lightweight web form
- the command line
- HTTP endpoint
Completed briefs can be sent directly to a Notion database, and a dry-run mode returns the complete result without changing anything.
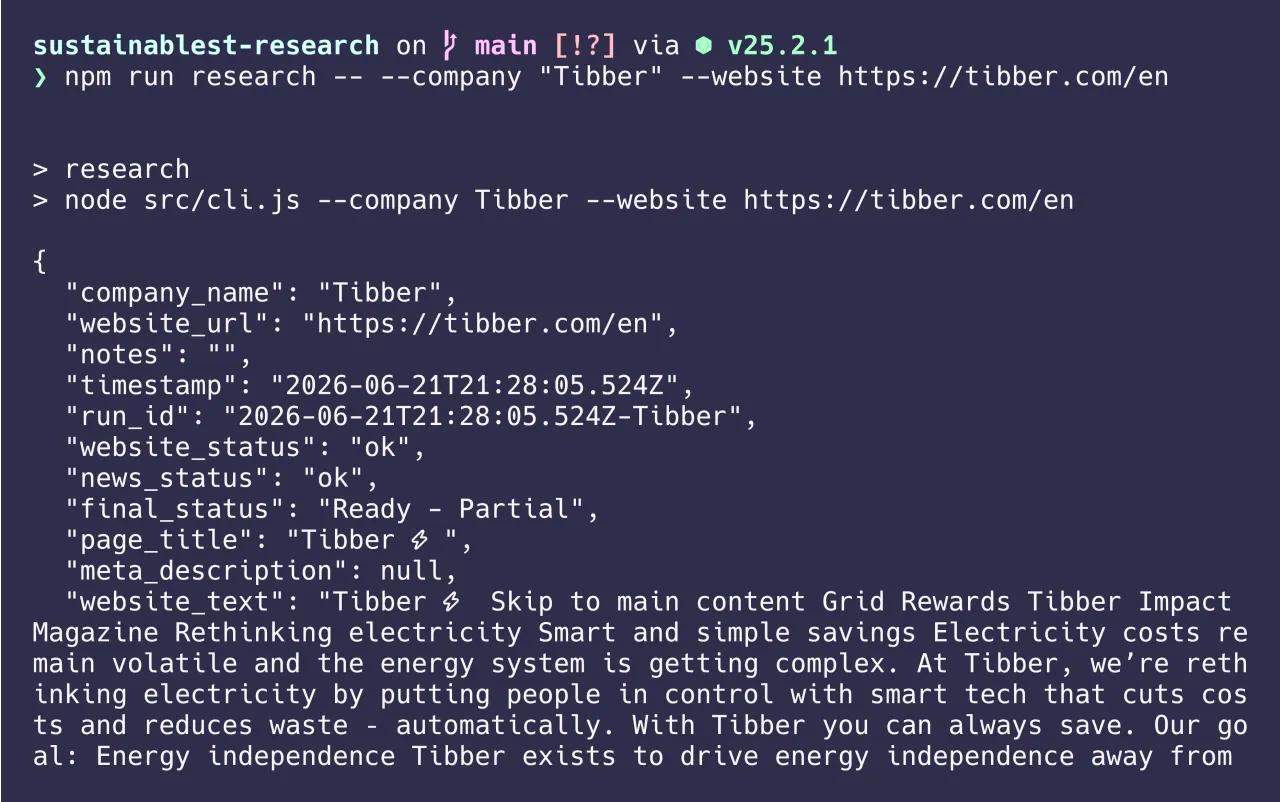
Why I made it
Researching a company for outreach is repetitive, pattern-based work that is prone to errors. Company websites can mix facts with marketing language, and manually searching for news can return weak or incorrect results. You can also run into confusion with similarly named businesses.
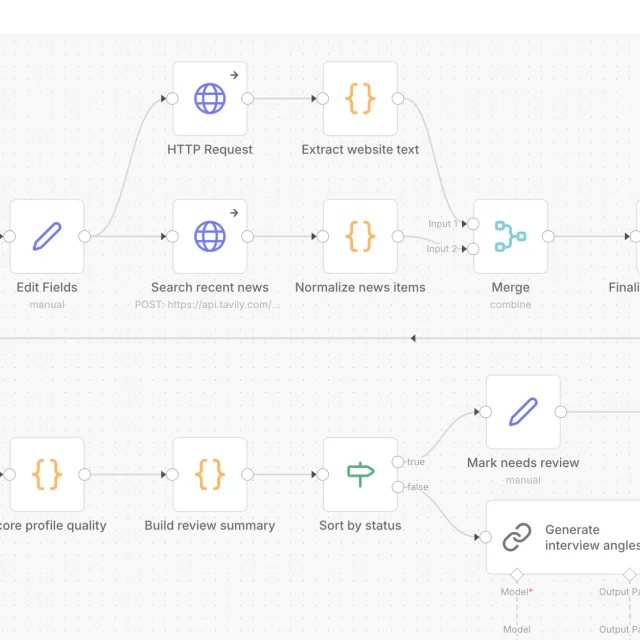
To make this research more efficient, I built a workflow. Originally, this was created in an n8n project that connected a form, website and news retrieval, language-model steps, quality checks, and a Notion database. This was a fast and easy way to test the idea and the complete flow, and the results were decent.
It wasn't perfect though, and because validation, scoring, and routing logic was distributed across visual nodes, it was tricky to improve. To create a production-quality system, I rebuilt the prototype workflow as a small Node.js service.
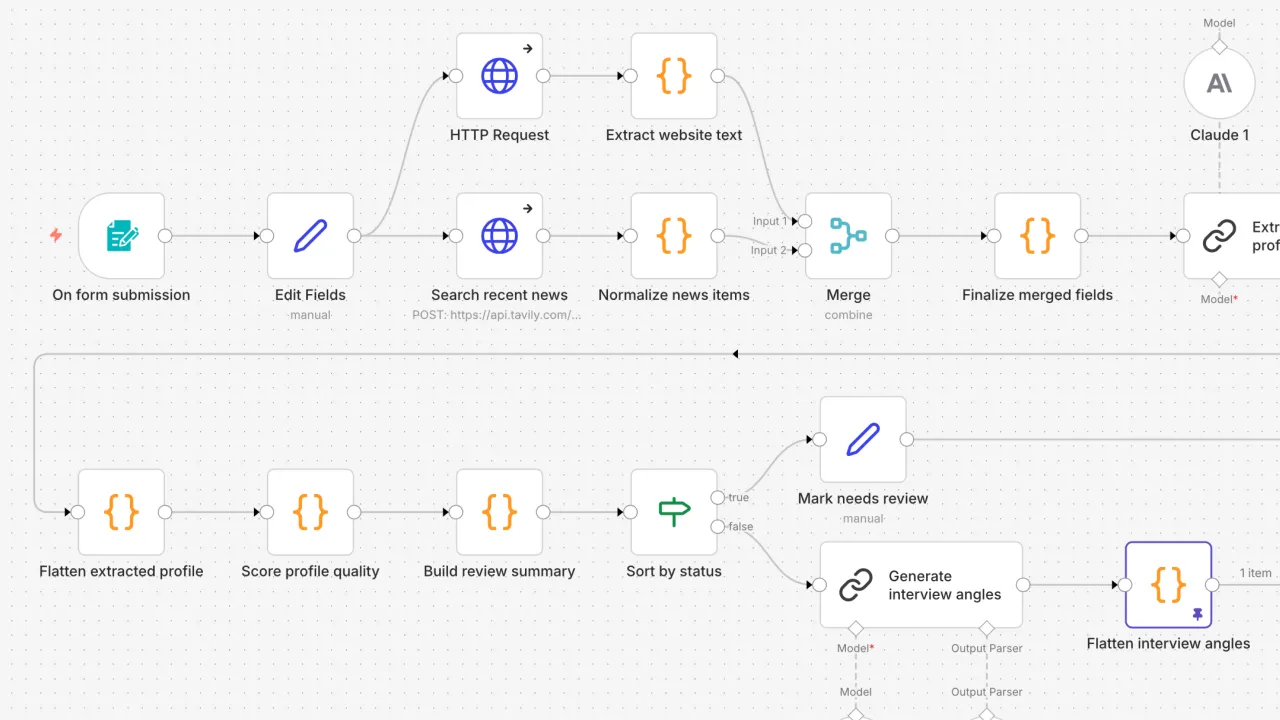
The problem
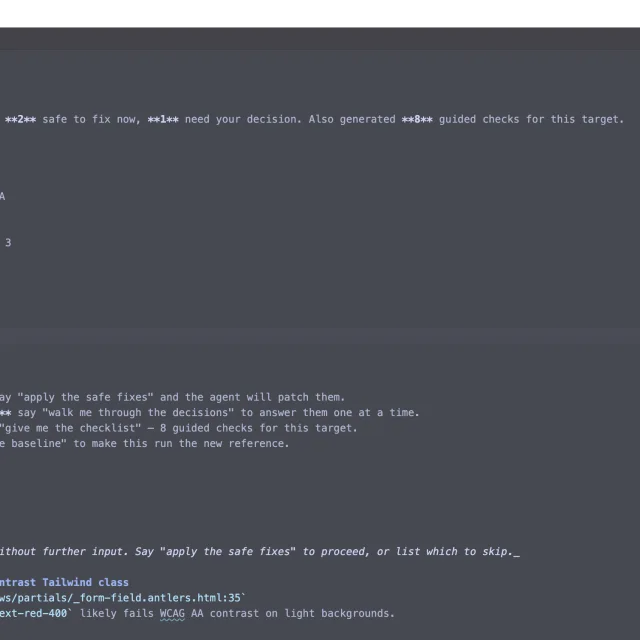
Rewriting the service immediately exposed weaknesses that had been hidden in the n8n prototype — details like the profile step whose parser could fail without notice and produce incorrect scores and statuses. It was easy to produce a company summary, but preventing the system from confidently delivering the wrong results was harder. A search for Octopus Energy, for example, can return coverage of Octopus Systems. When connected to enough related language, they may both appear relevant to a model even though they describe different organizations.
The question became: how much research can be automated without an unacceptable loss of accuracy?
The solution
The solution was to treat the language model as one component inside the editorial workflow, not the workflow itself. This was started in the prototype, but working with the code itself allowed the opportunity to bring precision through design.
In the updated version, code decides:
- which sources are admissible
- whether the returned profile matches the required structure
- whether important facts are missing
- whether the result can be used
Synthesis through the LLM only occurs after those checkpoints have been cleared.
How it works
1. Collection
The service fetches the company website and recent news in parallel.
News queries combine the company name with its website hostname, then pass the results through a conservative relevance filter before anything reaches the model.
2. Reject likely errors
For multi-word company names, an article needs to contain the complete company phrase. Results that appear to refer to another organization are rejected with an explanation:
matched different entity: octopus systems
This might result in discarding an article that uses a shortened company name, but it’s worth it. Combining two organizations into one profile is .
3. Extract into the profile
The profile has an explicit structure, and every required key needs to be present, including source notes and separate website and news evidence.
Unknown facts can be null. Missing keys, malformed evidence, and the wrong number of interview outputs are validation errors.
If the first response fails validation, the service sends the errors back for one attempt at repair. If it still fails, the result is marked invalid and requiring review.
4. Score quality and control permission
Each brief receives a quality score based on:
- source availability
- extraction validity
- missing fields
The score contributes to one of three workflow states:
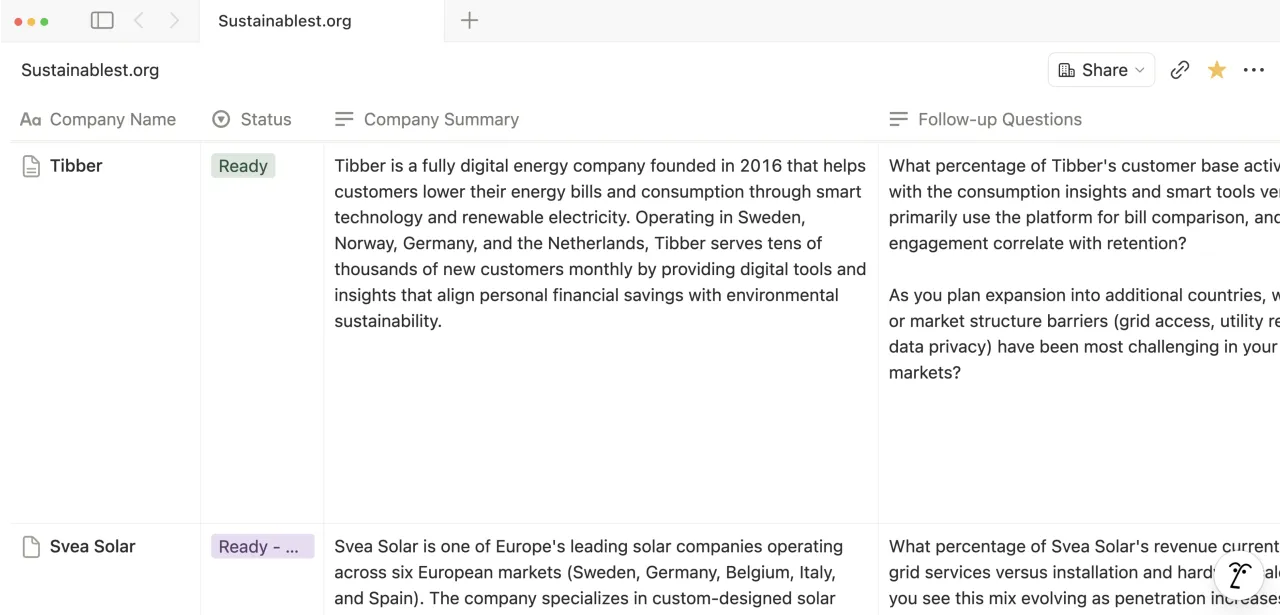
- Ready — complete to a sufficient degree and can be used
- Ready – Partial — usable, with some fields missing
- Needs Review — invalid, critically incomplete, or below the quality threshold
The state controls what happens next.
Interview angles, outreach hooks, and follow-up questions are generated when the profile is marked Ready or Ready – Partial.
5. Deliver the result
The same pipeline is available through:
- a minimal local web form;
- a
POST /researchendpoint; - a command-line workflow for one-off or scripted runs;
- an optional Notion writer for completed briefs.
A dry-run mode is available for testing results. This mode doesn't add results to Notion.
What exists now
The repository contains a working Node.js research service with:
- website and recent-news collection
- entity filtering
- Anthropic-based structured extraction
- runtime schema validation and repair attempts
- quality scoring and review routing
- conditional interview-angle generation
- optional Notion output
- web, API, and command-line interfaces
- automated tests for high-risk validation and routing behaviour
The project is an evolving internal tool that can complete the research workflow end-to-end.
What I learned
Planning is the key to getting good results. Source selection, explicit schemas, failure handling, and downstream permissions have more influence on trustworthiness than instructing a model to be accurate. A model can turn research into a useful brief, but only when the rest of the product has already set up boundaries for the LLM.
Fast prototyping continues to deliver the most valuable wins in projects — the visual workflow helped me understand the basic structure quickly, an rebuilding it in code forced me to confront its weaknesses and define what ready and failure meant for the results.
Above all, I learned that exposing uncertainty can be the key to success.
Where it could go
Further improvements could include stronger website extraction, a repeatable evaluation set for difficult company-name collisions, and monitoring that reveals when retrieval quality or model output begins to degrade.
Independent projects